01
Modélisation prédictive & aide à la décision
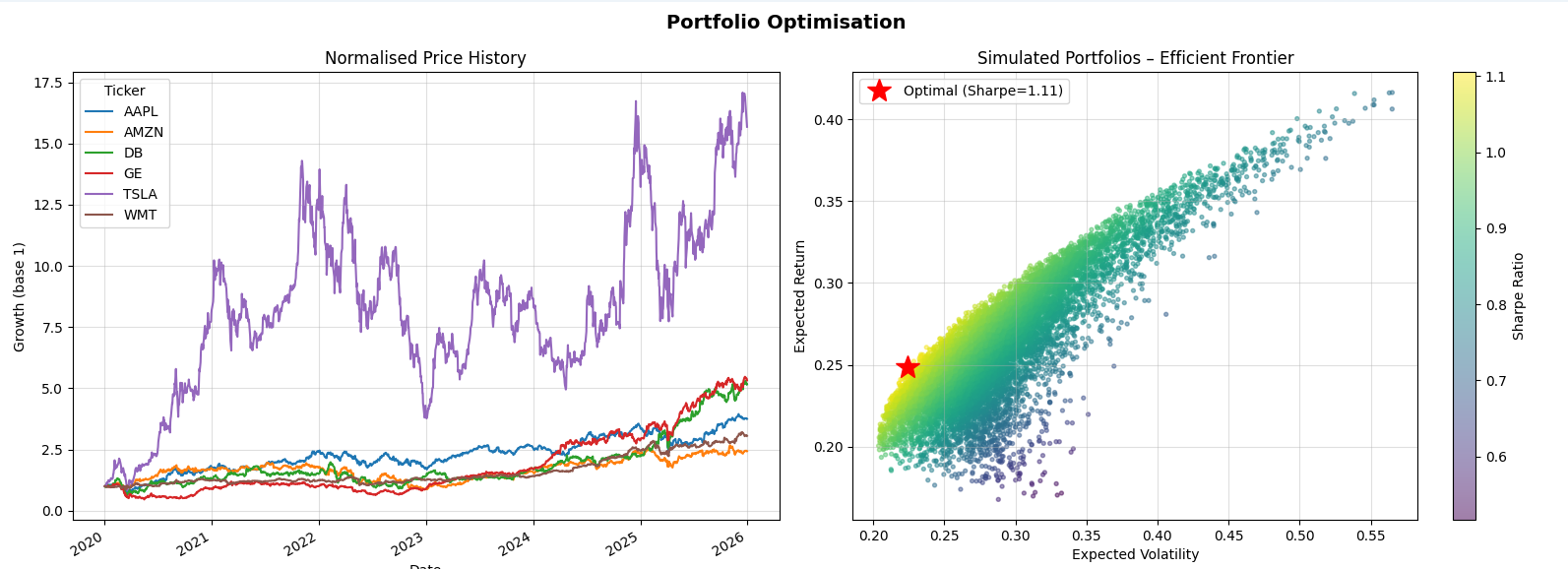
Je construis des modèles à partir de données réelles en partant toujours du problème à résoudre : comprendre les variables qui influencent un phénomène, quantifier leur impact et produire des estimations exploitables. Par exemple, j’ai travaillé sur la prédiction de valeurs immobilières en tenant compte des caractéristiques des biens et de leur localisation. J’utilise pour cela des méthodes statistiques et de machine learning, en veillant à interpréter les résultats et à en dégager des leviers d’action concrets.